An Introduction to Topic Modelling

Friday, April 13, 2018
Time: 12:00-3:00 pm
Location: UC Irvine Humanities Hall 251
About the WhatEvery1Says (WE1S) Project
- An initiative of 4humanities.org.
- Funded by the Andrew W. Mellon Foundation, will collaborators at UC Santa Barbara, California State University, Northridge, and the University of Miami.
- Goals:
- Use Digital Humanities methods to study public (especially journalistic) discourse about the Humanities at large data scales.
- Develop tools and guidelines to create an open, generalizable, and replicable methodology for doing topic modelling, which will make topic modelling easier to adopt for Humanities students and scholars.
- Website: http://we1s.ucsb.edu/.
What is Topic Modelling?
- A form of unsupervised machine learning used to identify categories of meaning in collections of texts.
- Developed for information search and retrieval.
- Increasingly employed by scholars of history and literature to model meaning in their texts.
Topic modelling begins with the insight that texts are constructed from building blocks called "topics".
Topic modelling algorithms use information in the texts themselves to generate these topics.
We can explore the results of this process in order to learn something about the texts that were used to create the model.
A topic model can produce amazing, magical insights about your texts...





Workshop Plan
- The text analysis workflow
- How topic modelling works
- What do you need to do topic modelling?
- Methodological and theoretical discussion
- Hands on practice (for those who want to stay)
The Text Analysis Workflow
What is Text Analysis?
(my current definition)
(Computationally) finding quantitative patterns in natural language samples and attributing meaning to these patterns.
Basic Workflow Steps
- Pre-Processing (e.g. removal of punctuation, stopwords, etc.)
- Statistical Processing (e.g. cluster analysis, topic modelling)
- Visualisation (using charts or graphs to explore data)
- Iterative Experimentation
- Constructing a Narrative of Meaning
Deformance
Pre-processing creates a “deformed” version of the original text for analysis.
Statistical processing transforms the text from natural language to quantitative data. This type of “deformance” typically involves dimensionality reduction, a simplification of the data so that it can be represented in two-dimensional space.
See Samuels, Lisa, and Jerome McGann. “Deformance and Interpretation.” New Literary History 30.1 (1999) : 25–56.
Narrative of Meaning
A “narrative of meaning” is an account of the significance of the results of text analysis.
Such a narrative must include an account of the decisions made as part of pre-processing, statistical processing, and visualisation steps in the workflow.
Useful Terminology
- Document: a whole text or a segment of a text.
- Token: an individual occurrence of a countable item in a document (typically a word).
- Term (also Type): A distinct form of a token that may occur one or more times in a document.
- Bag of Words: Set of tokens or terms lacking their order or placement in the original source text(s).
- Document-Term Matrix (DTM): A table showing the number of times each term occurs in each document.
Sample Workflow Using Lexos
How Topic Modelling Works
The Purpose of Topic Modelling
Topic modelling attempts to map out the semantic categories that make up a collection of documents.
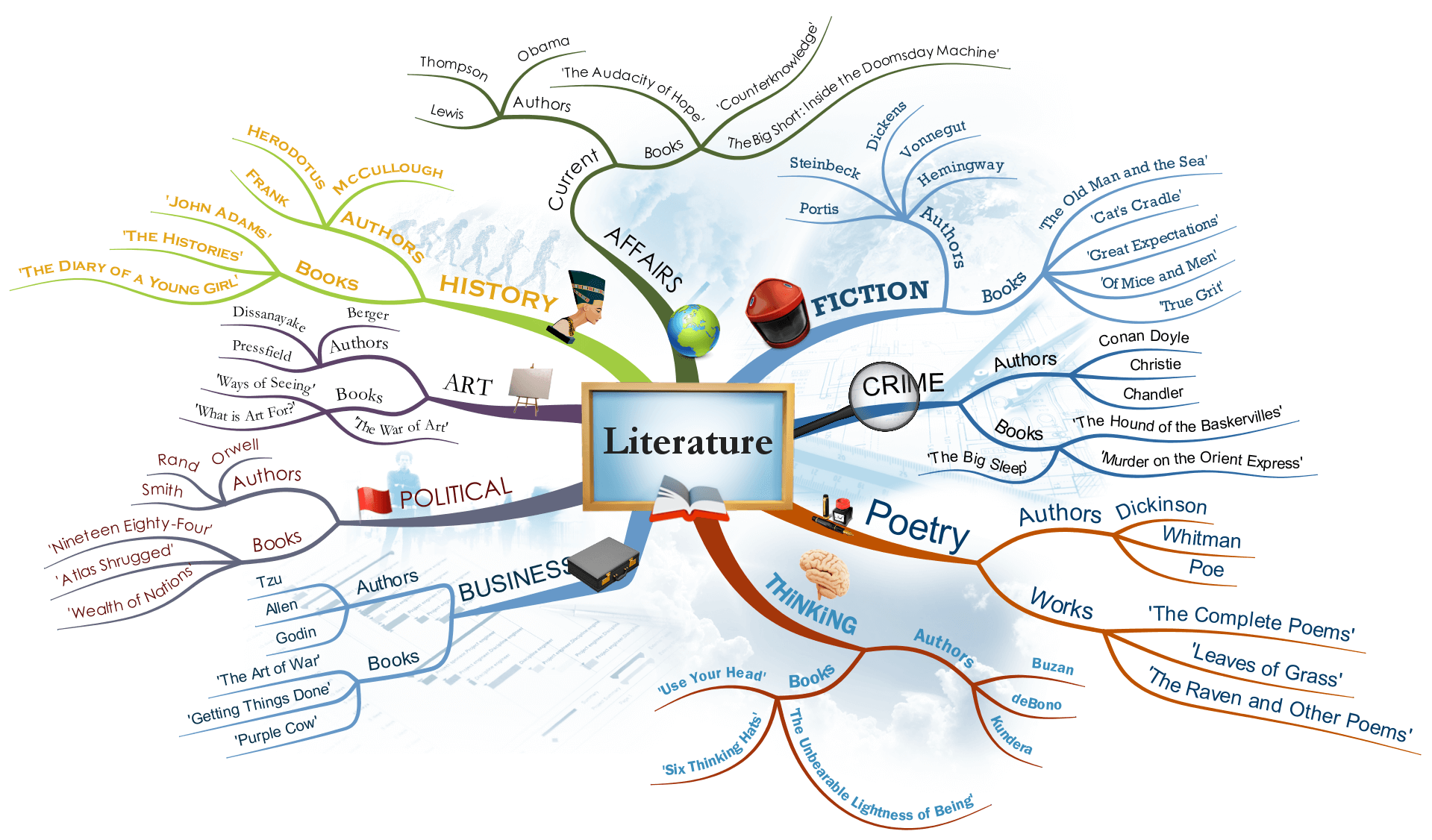
Source: iMindMap
What is a Topic?
Formal definition: A probability distribution over terms.
Informal definition: Some potentially meaningful category onto which we can map the terms and documents in our collection.
Working definition: A list of terms (usually words) from your document collection, each of which has a certain probability of occurring with the other terms in the list.
Where do topics come from?

Source: clipartxtras.com
Traditional v. Algorithmic Methods
Traditional methods relay on our contextual knowledge of the documents to identify something like topics.
Algorithmic approaches use only the information contained within the documents themselves to identify topics.*
* But they are typically tuned by human decisions which require some prior assumptions and disciplinary understanding of the material.
Topic Modelling is a Generative Approach
It uses an algorithm to generate the topics by examining the tendency of individual terms to occur together in the same documents.
In other words, topics are inferred from the documents themselves.
One of the most popular algorithms is Latent Dirichlet Allocation (LDA).
Assumptions
- All documents are constructed out of some finite set of topics.
- We do not know what these topics are.
- We can reverse engineer at least some of the topics from whatever limited number documents available to us.
Process
- Start by choosing a number of topics to examine.
- Use this number to randomly assign the vocabulary in our documents to bags of words.
- Make this assignment less random by moving words into different bags according to (a) how much of the vocabulary currently in each bag is represented in the document and (b) which bag has the word most prominently represented.
- Repeat this process until we are satisfied that the vocabulary in each bag belongs together.
Voilà! Each bag of words is a “topic”.
Learning More about LDA
Matthew Jockers, “The LDA Buffet is Now Open; or, Latent Dirichlet Allocation for English Majors”
Ted Underwood, “Topic modeling made just simple enough”
Follow the links in Scott Weingart, “Topic Modeling for Humanists: A Guided Tour” (provides a gentle pathway into the statistical intricacies)
Christof Schöch, “Topic Modeling Workshop: Beyond the Black Box https://christofs.github.io/topic-modeling-edinburgh/#/”.
Ted Underwood’s Diagram of a Topic Model
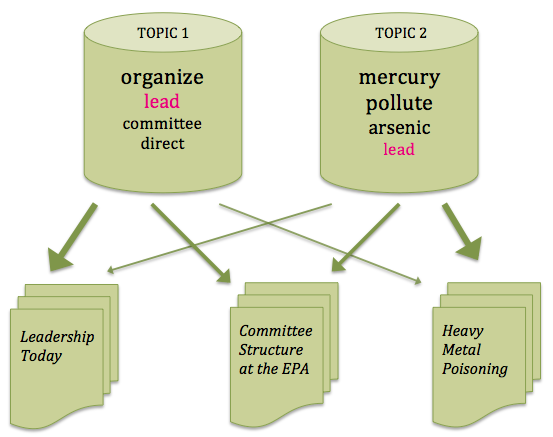
Source: Ted Underwood, “Topic modeling made just simple enough”
Topic Model of US Humanities Patents
| Topic | Prominence | Keywords |
|---|
| 0 | 0.05337 | atlanta buck sherman coffee lil city soldiers union donaldson war opera music men dance wrote vamp |
| 1 | 0.03937 | chinese singapore quantum scientific china percent han evidence xinjiang physics bjork language study ethnic test culture pretest memory miksic |
| 2 | 0.06374 | dr medical pain osteopathic medicine brain patients doctors creativity care health smithsonian touro patient benson cancer physician skorton physicians |
| 3 | 0.12499 | book poetry books literary writer writers american literature fiction writing poet author freud english novels culture published review true |
| 4 | 0.14779 | museum art mr ms arts museums artist center artists music hong kong contemporary works director china painting local institute |
| 5 | 0.0484 | love robinson mr godzilla slater gorman movie mother lila literature read sachs happy taught asked writing house child lived |
| 6 | 0.03013 | oct org street nov center museum art gallery sundays saturdays theater free road noon arts connecticut tuesdays avenue university |
| 7 | 0.09138 | johnson rights editor mr wilson poverty civil war vietnam kristof president writer jan ants hope human bill lyndon presidents |
| 8 | 0.18166 | technology computer business ms tech engineering jobs mr women people science percent ireland work skills companies fields number company |
| 9 | 0.08085 | israel women police violence black gender war church poland white northern officers country trial racism rights civil justice rice |
| 10 | 0.94475 | advertisement people time years work make life world year young part day made place back great good times things |
| 11 | 0.08681 | mr chief smith russian vista company russia financial times equity dealbook million reports street private berggruen york bank executive |
| 12 | 0.1135 | street york show free sunday children saturday theater city monday tour friday martin center members students manhattan village west |
| 13 | 0.17297 | times video photo community commencement article york lesson credit read tumblr online students blog digital college plan twitter news |
| 14 | 0.4395 | university american research mr studies international faculty state center work dr director arts universities academic bard advertisement education history |
| 15 | 0.55649 | people human world professor science humanities time knowledge life questions study learn social find ways change thinking problem don |
| 16 | 0.10946 | mr ms professor marriage york wrote degree newark mondale mother born received father school aboulela ajami price married home |
| 17 | 0.3896 | years government mr president report programs public american humanities state ms year million information board budget today left private |
| 18 | 0.07622 | religion religious buddhist faith philosophy traditions god derrida philosophers life beliefs hope buddhism jesus doctrine stone deconstruction theology lives |
| 19 | 0.31793 | students school education college schools student teachers teaching graduate year harvard percent colleges class high graduates job learning universities |
Topic model data courtesy of Alan Liu.
What do Topic Models Tell Us?
- The topics present in the collection.
- The prominence of individual topics in the collection.
- The prominence of individual terms in each topic.
- The prominence of each topic in each document in the collection.
- The most prominent documents associated with each topic.
The results of topic modelling often combine the familiar with the surprising.

Examples of Topic Modelling
What do you need
to do topic modelling?
Implementations
The most popular implementation used by digital humanists is MALLET (written in Java).
You can run MALLET as a desktop app with the GUI Topic Modeling tool. This is an especially useful for students.
Good implementations are available for the Python and R programming languages (the Python gensim library is very accessible).
Why should I run MALLET from the command line instead of using the GUI Topic Modeling Tool?
You get the latest version.
A few MALLET functions are not implemented in the GUI Topic Modeling Tool, such as random-seed, which ensures that topic models are reproducible.
Tutorials
The Programming Historian, “Getting Started with Topic Modeling and MALLET”
DARIAH-DE, Text Analysis with Topic Models for the Humanities and Social Sciences (Python and MALLET)
Beginners Guide to Topic Modeling in Python (uses the Python gensim)
Matthew Jockers, Text Analysis with R for Students of Literature
Visualisation
![Edvard Munch [Public domain], The Scream](images/Edvard_Munch_-_The_Scream_-_Google_Art_Project.jpg)
{kind=link}
Lexos Multiclouds
Serendip

Other Options
See the WhatEvery1Says Report on Topic Modeling Interfaces for an overview of other methods of visualising topic models.
The WhatEvery1Says Virtual Workspace
(Coming Soon)
Methodological and Theoretical
Discussion
Practical Questions
- How do we choose the number of topics and other options (AKA “priors” or “hyperparameters”) in constructing our model?
- How do we evaluate the quality of our results?
What do Topics Represent?
- Subjects
- Themes
- Discourses
- Meaningless junk
Good topics are normally judged by the “semantic coherence” of their terms, but there is proven statistical heuristic for demonstrating this.
Typically, human intuition is used to label the topics (e.g. Religion and Deconstructionism: religion religious buddhist faith philosophy traditions god derrida ...).
Less semantically coherent topics can be the most interesting because they bring together terms human users might not relate.
Junk topics can be ignored, but a “good” topic model will have a relatively low percentage of junk topics.
How closely does the model correspond to “reality”?
If each stage is a transformation (“deformance”) of the source text, how do we relate the results of this transformation to the original?
How does the size and nature of our data affect the results of topic modelling?
What human decisions influence the construction of the model?
Other thoughts or questions?
Hands-On Workshop
Tools
- The GUI Topic Modeling Tool (Download at https://bit.ly/2v1XRMZ)
- Lexos Multiclouds
- MALLET from the command line (if we have time)
Installing the GUI Topic Modeling Tool
| Mac | Windows |
|---|---|
1. Download TopicModelingTool.dmg.2. Open it by double-clicking. 3. Drag the app into your Applications folder – or into any folder at all. 4. Run the app by double-clicking. |
1. Download TopicModelingTool.zip.2. Extract the files into any folder. 3. Open the folder containing the files. 4. Double-click on the file called TopicModelingTool.exe to run it.
|
On the Mac, if you get an error saying that the file is from an “unidentified developer”, press control while double-clicking. You will be given an option to run the file.
- Set up your workspace by creating an
inputdirectory and anoutputdirectory. Dump your text collection in the former. All documents should be text files in the same directory. - Launch the Topic Modeling Tool. Check out the Quickstart Guide file for help using the tool.
Create a Project
- Make a new project folder (call it something like
tm_project). - Inside it, create a folder called
inputand a folder calledoutput. - Drag your text collection into the
inputfolder.
Important: All texts should be in plain text format, and all files should be at the same level. If you find yourself encountering problems with character encoding, read the advice in the Quickstart Guide.
Need some data? There are some sample sets in the workshop sandbox: https://bit.ly/2Hfk3YP.
First Steps
- Launch the GUI Topic Modeling Tool if you have not done so already.
- Select your input and output folders.
- Click
Learn Topics. - When the process is finished, go to your
outputfolder and explore the contents. Look especially at theoutput_htmlfolder and openall_topics.htmlin a browser.
Setting Options
- Inside your project folder, create a new folder called
output2. In the GUI Topic Modeling Tool, set that as the new output folder. - Change the
Number of Topicsto “20”. - Click the
Optional settings...button. - Click the
Preserve raw MALLET outputcheckbox and change the number of topic words to print to “10”. ClickOK. - Click
Learn Topics - When the process is finished, go to your
output2folder and openall_topics.htmlin a browser. What differences are there?
Visualising Models with Lexos Multiclouds
- In your browser, go to http://lexos.wheatoncollege.edu/multicloud.
- Click the
Document Cloudstoggle so that it readsTopic Clouds. - Click the
Upload Filebutton. In youroutput2folder, find the filewords-topic-counts.txtin theoutput_malledfolder and select it. - Click
Get Graphs. The multiclouds will take time to generate and your browser may freeze. Be patient. - Once the clouds are generated, you can drag and drop them into different orders to compare topics.
- If you click
Convert topics to documents, your topics will be converted into “texts” which you can explore with the other features of Lexos (e.g. cluster analysis). - Click the “In the Margins” tab on the left side of the screen for advice on how to save multiclouds.
Using Stopwords
- Download the
stopwords.txtfile from the workshop sandbox repository (https://bit.ly/2Hfk3YP). - In your project folder, create a new folder called
output3. In the GUI Topic Modeling Tool, set that as the new output folder. - Click the
Optional settings...button. - Uncheck the
Remove default English stopwords. - Click the
Stopword file...button and selectstopwords.txt. ClickOK. - Click
Learn Topics - When the process is finished, go to your
output3folder and openall_topics.htmlin a browser. What differences are there?
Iterations and Hyperparameters
- In your project folder, create a new folder called
output4. In the GUI Topic Modeling Tool, set that as the new output folder. - Click the
Optional settings...button and select the options you wish to use. - Set the number of iterations to more or less than “400”. Click
OK. - Click
Learn Topics - When the process is finished, go to your
output4folder and explore the differences. - You may wish to repeat the process by changing the
Interval between hyperprior optimizations(also referred to as "hyperparameter optimization"). In short, this allows more general topics to be more prominent in the model. For a fuller explanation, see Christof Schöch's “Topic Modeling with MALLET: Hyperparameter Optimization”.
What Next?
- Play with the
Metadatatool as documented in the Quickstart Guide. - Install the command line version of MALLET so that you can use the
--random-seedcommand to get reproducible results. - Follow the DARIAH-DE Text Analysis with Topic Models for the Humanities and Social Sciences tutorial to combine topic modelling with other Python-based text analysis.
- Experiment with Python's `gensim` library or R-based implementations of topic modelling.
The End
Slideshow produced by Scott Kleinman.
Sponsored by UC Irvine, Humanities Commons
and the WhatEvery1Says Project.

